
shinka is a framework that combines Large Language Models (LLMs) with evolutionary algorithms to drive scientific discovery. By leveraging the creative capabilities of LLMs and the optimization power of evolutionary search, shinka enables automated exploration and improvement of scientific code. The system is inspired by the AI Scientist, AlphaEvolve and the Darwin Goedel Machine: It maintains a population of programs that evolve over generations, with an ensemble of LLMs acting as intelligent mutation operators that suggest code improvements.
Mar 2026 Update: Refactored API and unified runner ShinkaEvolveRunner (replacing EvolutionRunner and AsyncEvolutionRunner). You can now install shinka via PyPI and uv: pip install shinka-evolve.
Feb 2026 Update: Added agent skills for using shinka within coding agents (Claude Code, Codex, etc.) for new task generation (shinka-setup), converting your repo (shinka-convert), evolution (shinka-run), and result inspection (shinka-inspect). Install them via npx:
npx skills add SakanaAI/ShinkaEvolve --skill '*' -a claude-code -a codex -y
Jan 2026 Update: ShinkaEvolve was accepted at ICLR 2026 and we have released v1.1 with many new features.
Nov 2025 Update: Rob gave several public talks about our ShinkaEvolve effort (Official, AutoML Seminar).
Oct 2025 Update ShinkaEvolve supported Team Unagi in winning the ICFP 2025 Programming Contest.
The framework supports parallel evaluation of candidates locally or on a Slurm cluster. It maintains an archive of successful solutions, enabling knowledge transfer between different evolutionary islands. shinka is particularly well-suited for scientific tasks where there is a verifier available and the goal is to optimize performance metrics while maintaining code correctness and readability.
| Guide | Description | What You'll Learn |
|---|---|---|
| 🚀 First steps | Installation, basic usage, and examples | Setup, first evolution run, core concepts |
| 📓 Tutorial | Interactive walkthrough of Shinka features | Hands-on examples, configuration, best practices |
| ⚙️ Configuration | Comprehensive configuration reference | All config options, optimization settings, advanced features |
| 🎨 WebUI | Interactive visualization and monitoring | Real-time tracking, result analysis, debugging tools |
| ⚡ Async Evo | High-performance async pipeline (5-10x speedup) | Concurrent processing, proposal/eval concurrency tuning |
| 🧠 Local LLM | How to connect and use local LLMs with Shinka | Running open-source models, integration tips, performance notes |
| 🤖 Agentic Use | Run Shinka with Claude/Codex skills | CLI install, skill placement, setup/run workflows |
# Install from PyPI
pip install shinka-evolve
# Or with uv
uv pip install shinka-evolve
# Run your first evolution experiment
shinka_launch variant=circle_packing_exampleThe distribution name is shinka-evolve; Python imports stay import shinka.
shinka_launch still supports the original shorthand group overrides:
shinka_launch variant=circle_packing_example
shinka_launch task=novelty_generator database=island_smallBuilt-in Hydra presets ship inside the package under shinka/configs/. To add your own presets from a PyPI install without cloning the repo, place them in your own config directory and pass --config-dir:
mkdir -p ~/my-shinka-configs/variant
$EDITOR ~/my-shinka-configs/variant/my_variant.yaml
shinka_launch --config-dir ~/my-shinka-configs variant=my_variantFor development installs from source:
git clone https://github.com/SakanaAI/ShinkaEvolve
cd ShinkaEvolve
uv venv --python 3.11
source .venv/bin/activate # On Windows: .venv\Scripts\activate
uv pip install -e .For detailed installation instructions and usage examples, see the Getting Started Guide.
| Example | Description | Environment Setup |
|---|---|---|
| ⭕ Circle Packing | Optimize circle packing to maximize radii. | LocalJobConfig |
| 🎮 Game 2048 | Optimize a policy for the Game of 2048. | LocalJobConfig |
| ∑ Julia Prime Counting | Optimize a Julia solver for prime-count queries. | LocalJobConfig |
| ✨ Novelty Generator | Generate creative, surprising outputs (e.g., ASCII art). | LocalJobConfig |
For the simplest setup with default settings, you only need to specify the evaluation program:
from shinka.core import ShinkaEvolveRunner, EvolutionConfig
from shinka.database import DatabaseConfig
from shinka.launch import LocalJobConfig
# Minimal - only specify what's required
job_conf = LocalJobConfig(eval_program_path="evaluate.py")
# Or source a uv/venv environment per job:
# job_conf = LocalJobConfig(
# eval_program_path="evaluate.py",
# activate_script=".venv/bin/activate",
# )
db_conf = DatabaseConfig()
evo_conf = EvolutionConfig(init_program_path="initial.py")
runner = ShinkaEvolveRunner(
evo_config=evo_conf,
job_config=job_conf,
db_config=db_conf,
max_evaluation_jobs=2,
max_proposal_jobs=1, # sync-like proposal behavior
)
runner.run()EvolutionConfig Parameters (click to expand)
Class defaults below come from shinka/core/config.py (EvolutionConfig). Hydra presets and CLI overrides can replace these values.
| Key | Default Value | Type | Explanation |
|---|---|---|---|
task_sys_msg |
"You are an expert optimization and algorithm design assistant. Improve the program while preserving correctness and immutable regions." |
Optional[str] |
System message describing the optimization task |
patch_types |
["diff", "full", "cross"] |
List[str] |
Types of patches to generate: "diff", "full", "cross" |
patch_type_probs |
[0.6, 0.3, 0.1] |
List[float] |
Probabilities for each patch type |
num_generations |
50 |
int |
Number of evolution generations to run |
max_proposal_jobs |
1 |
int |
Maximum number of concurrent proposal generation jobs |
max_db_workers |
4 |
int |
Maximum number of async DB worker threads |
max_patch_resamples |
3 |
int |
Max times to resample a patch if it fails |
max_patch_attempts |
1 |
int |
Max attempts to generate a valid patch |
job_type |
"local" |
str |
Job execution type: "local", "slurm_docker", "slurm_conda" |
language |
"python" |
str |
Programming language for evolution |
llm_models |
["gpt-5-mini", "gemini-3-flash-preview", "gemini-3.1-pro-preview", "gpt-5.4"] |
List[str] |
List of LLM models for code generation |
llm_dynamic_selection |
"ucb" |
Optional[Union[str, BanditBase]] |
Dynamic model selection strategy |
llm_dynamic_selection_kwargs |
{"cost_aware_coef": 0.5} |
dict |
Kwargs for dynamic selection |
llm_kwargs |
{"temperatures": [0.0, 0.5, 1.0], "max_tokens": 16384} |
dict |
Additional kwargs for LLM calls |
meta_rec_interval |
10 |
Optional[int] |
Interval for meta-recommendations |
meta_llm_models |
None |
Optional[List[str]] |
LLM models for meta-recommendations |
meta_llm_kwargs |
{} |
dict |
Kwargs for meta-recommendation LLMs |
meta_max_recommendations |
5 |
int |
Max number of meta-recommendations |
sample_single_meta_rec |
True |
bool |
Sample a single recommendation from meta output when enabled |
embedding_model |
"text-embedding-3-small" |
Optional[str] |
Model for code embeddings |
init_program_path |
"initial.py" |
Optional[str] |
Path to initial program to evolve |
results_dir |
None |
Optional[str] |
Directory to save results (auto-generated if None) |
max_novelty_attempts |
3 |
int |
Max attempts for novelty generation |
code_embed_sim_threshold |
0.99 |
float |
Similarity threshold for code embeddings |
novelty_llm_models |
None |
Optional[List[str]] |
LLM models for novelty judgment |
novelty_llm_kwargs |
{} |
dict |
Kwargs for novelty LLMs |
use_text_feedback |
False |
bool |
Whether to use text feedback in evolution |
max_api_costs |
None |
Optional[float] |
Total API budget cap (USD); async runner stops new proposals at cap |
inspiration_sort_order |
"ascending" |
str |
Inspiration ordering ("ascending", "chronological", "none") |
evolve_prompts |
False |
bool |
Enable meta-prompt evolution loop |
prompt_patch_types |
["diff", "full"] |
List[str] |
Patch formats used for prompt evolution |
prompt_patch_type_probs |
[0.7, 0.3] |
List[float] |
Sampling probabilities for prompt patch formats |
prompt_evolution_interval |
None |
Optional[int] |
Prompt-evolution cadence in generations (None disables periodic updates) |
prompt_archive_size |
10 |
int |
Size of system-prompt archive |
prompt_llm_models |
None |
Optional[List[str]] |
LLM models for prompt evolution (None falls back to llm_models) |
prompt_llm_kwargs |
{} |
dict |
Extra kwargs for prompt-evolution LLM calls |
prompt_ucb_exploration_constant |
1.0 |
float |
UCB exploration constant for prompt sampling |
prompt_epsilon |
0.1 |
float |
Epsilon-greedy exploration probability for prompt sampling |
prompt_evo_top_k_programs |
3 |
int |
Number of top programs used as context in prompt evolution |
prompt_percentile_recompute_interval |
20 |
int |
Generations between prompt percentile recomputations |
DatabaseConfig Parameters (click to expand)
Class defaults below come from shinka/database/dbase.py (DatabaseConfig). Hydra presets and CLI overrides can replace these values.
| Key | Default Value | Type | Explanation |
|---|---|---|---|
db_path |
None |
Optional[str] |
Database file path (auto-generated if None) |
num_islands |
2 |
int |
Number of evolution islands for diversity |
archive_size |
40 |
int |
Global archive size cap |
elite_selection_ratio |
0.3 |
float |
Proportion of elite programs for inspiration |
num_archive_inspirations |
1 |
int |
Number of archive programs to use as inspiration |
num_top_k_inspirations |
1 |
int |
Number of top-k programs for inspiration |
migration_interval |
10 |
int |
Generations between island migrations |
migration_rate |
0.0 |
float |
Proportion of island population to migrate |
island_elitism |
True |
bool |
Keep best programs on their original islands |
enforce_island_separation |
True |
bool |
Enforce full separation between islands |
island_selection_strategy |
"uniform" |
str |
Island sampler ("uniform", "equal", "proportional", "weighted") |
enable_dynamic_islands |
False |
bool |
Enable stagnation-triggered island spawning |
stagnation_threshold |
100 |
int |
Generations without improvement before spawning a new island |
island_spawn_strategy |
"initial" |
str |
New-island seed strategy ("initial", "best", "archive_random") |
island_spawn_subtree_size |
1 |
int |
Number of programs copied when spawning an island |
parent_selection_strategy |
"weighted" |
str |
Parent selection: "weighted", "power_law", "beam_search" |
exploitation_alpha |
1.0 |
float |
Power-law exponent (0=uniform, 1=power-law) |
exploitation_ratio |
0.2 |
float |
Chance to pick parent from archive |
parent_selection_lambda |
10.0 |
float |
Sharpness of sigmoid for weighted selection |
num_beams |
5 |
int |
Number of beams for beam search selection |
archive_selection_strategy |
"fitness" |
str |
Archive replacement strategy ("fitness" or "crowding") |
archive_criteria |
{"combined_score": 1.0} |
Dict[str, float] |
Weighted ranking criteria used by fitness archive updates |
JobConfig Parameters (click to expand)
LocalJobConfig (for local execution):
| Key | Default Value | Type | Explanation |
|---|---|---|---|
eval_program_path |
"evaluate.py" |
Optional[str] |
Path to evaluation script |
extra_cmd_args |
{} |
Dict[str, Any] |
Additional command line arguments |
time |
None |
Optional[str] |
Time limit for job execution |
conda_env |
None |
Optional[str] |
Conda environment to run jobs in |
activate_script |
None |
Optional[str] |
Sourceable env script path, e.g. .venv/bin/activate |
SlurmDockerJobConfig (for SLURM with Docker):
| Key | Default Value | Type | Explanation |
|---|---|---|---|
eval_program_path |
"evaluate.py" |
Optional[str] |
Path to evaluation script |
extra_cmd_args |
{} |
Dict[str, Any] |
Additional command line arguments |
image |
"ubuntu:latest" |
str |
Docker image to use |
image_tar_path |
None |
Optional[str] |
Path to Docker image tar file |
docker_flags |
"" |
str |
Additional Docker flags |
partition |
"gpu" |
str |
SLURM partition to use |
time |
"01:00:00" |
str |
Job time limit |
cpus |
1 |
int |
Number of CPUs to request |
gpus |
1 |
int |
Number of GPUs to request |
mem |
"8G" |
Optional[str] |
Memory to request |
SlurmCondaJobConfig / SlurmEnvJobConfig (for SLURM with sourced or Conda environments):
| Key | Default Value | Type | Explanation |
|---|---|---|---|
eval_program_path |
"evaluate.py" |
Optional[str] |
Path to evaluation script |
extra_cmd_args |
{} |
Dict[str, Any] |
Additional command line arguments |
conda_env |
"" |
str |
Conda environment name |
activate_script |
None |
Optional[str] |
Sourceable env script path, e.g. .venv/bin/activate |
modules |
[] |
Optional[List[str]] |
Environment modules to load |
partition |
"gpu" |
str |
SLURM partition to use |
time |
"01:00:00" |
str |
Job time limit |
cpus |
1 |
int |
Number of CPUs to request |
gpus |
1 |
int |
Number of GPUs to request |
mem |
"8G" |
Optional[str] |
Memory to request |
conda_env and activate_script are mutually exclusive.
To use ShinkaEvolveRunner, you need two key files: The evaluate.py script defines how to test and score your programs - it runs multiple evaluations, validates results, and aggregates them into metrics that guide the shinka evolution loop. The initial.py file contains your starting solution with the core algorithm that will be iteratively improved by LLMs across generations.
|
from shinka.core import run_shinka_eval
def main(program_path: str,
results_dir: str):
metrics, correct, err = run_shinka_eval(
program_path=program_path,
results_dir=results_dir,
experiment_fn_name="run_experiment",
num_runs=3, # Multi-evals to aggreg.
run_workers=1, # >1 => per-run parallel
get_experiment_kwargs=get_kwargs,
aggregate_metrics_fn=aggregate_fn,
validate_fn=validate_fn, # Optional
)
def get_kwargs(run_idx: int) -> dict:
return {"param1": "value", "param2": 42}
def aggregate_fn(results: list) -> dict:
score = results[0]
text = results[1]
return {
"combined_score": float(score),
"public": {...}, # shinka-visible
"private": {...}, # shinka-invisible
"extra_data": {...}, # store as pkl
"text_feedback": text, # str fb
}
if __name__ == "__main__":
# argparse program path & dir
main(program_path, results_dir) |
# EVOLVE-BLOCK-START
def advanced_algo():
# This will be evolved
return solution
# EVOLVE-BLOCK-END
def run_experiment(**kwargs):
"""Main called by evaluator"""
result = solve_problem(kwargs)
return result
def solve_problem(params):
solution = advanced_algo()
return solutionKey Points:
|
shinka Launcher utilizes Hydra to configure and launch evolutionary experiments effortlessly. It supports concise configuration via Hydra's powerful override syntax, making it easy to manage and iterate scientific explorations.
# Run with the shared default baseline
shinka_launch
# Run with custom parameters
shinka_launch \
task=circle_packing \
database=island_large \
evolution=small_budget \
cluster=local \
evo_config.num_generations=20For comprehensive configuration options and advanced usage, see the Configuration Guide.
shinka_run is a task-directory launcher for async evolution. It is designed for agent workflows and does not require Hydra config files.
# Inspect full interface (detailed help)
shinka_run --help
# Minimal run
shinka_run \
--task-dir examples/circle_packing \
--results_dir results/circle_agent_run \
--num_generations 20
# Run with keyword overrides
shinka_run \
--task-dir examples/circle_packing \
--results_dir results/circle_agent_custom \
--num_generations 50 \
--max-evaluation-jobs 6 \
--set db.num_islands=2 \
--set job.time=00:10:00 \
--set job.activate_script=.venv/bin/activate \
--set evo.llm_models='["gpt-5-mini","gemini-3-flash-preview"]'
# Load optional YAML config (relative to --task-dir), then override via --set
shinka_run \
--task-dir examples/circle_packing \
--config-fname shinka_small.yaml \
--results_dir results/circle_agent_from_yaml \
--num_generations 50 \
--set db.num_islands=2--task-dir must contain evaluate.py and initial.<ext>.
--config-fname can define evo/db/job (or evo_config/db_config/job_config) plus max_evaluation_jobs/max_proposal_jobs/max_db_workers and verbose/debug.
Precedence: config YAML < --set < authoritative flags.
--results_dir and --num_generations are authoritative and always override config/--set values for evo.results_dir and evo.num_generations.
Monitor your evolution experiments in real-time with Shinka's interactive web interface! The WebUI provides live visualization of the evolutionary process, genealogy trees, and performance metrics.
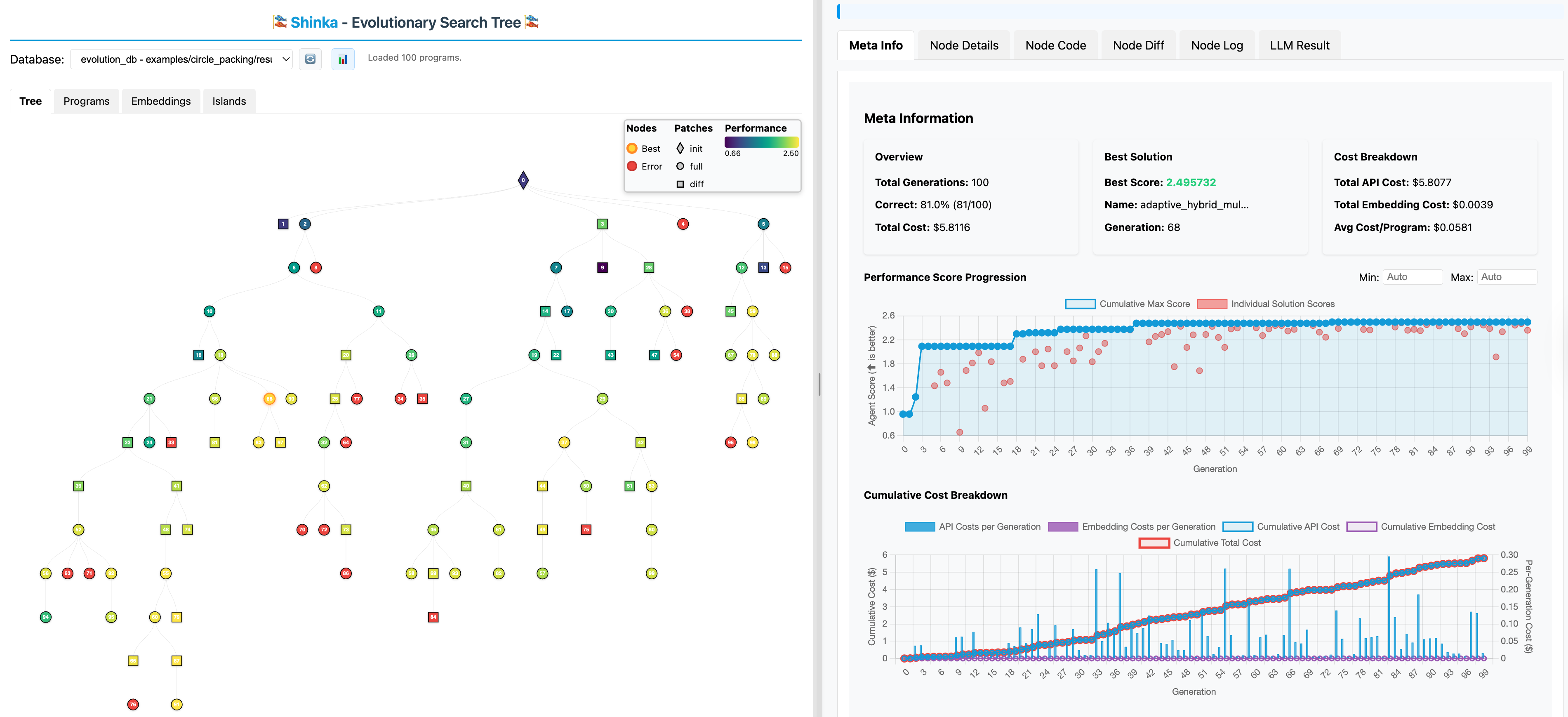
Launch the WebUI alongside your evolution experiment:
# Start your evolution experiment
shinka_launch
# In another terminal, launch the WebUI
shinka_visualize --port 8888 --openFor detailed WebUI documentation, see the WebUI Guide.
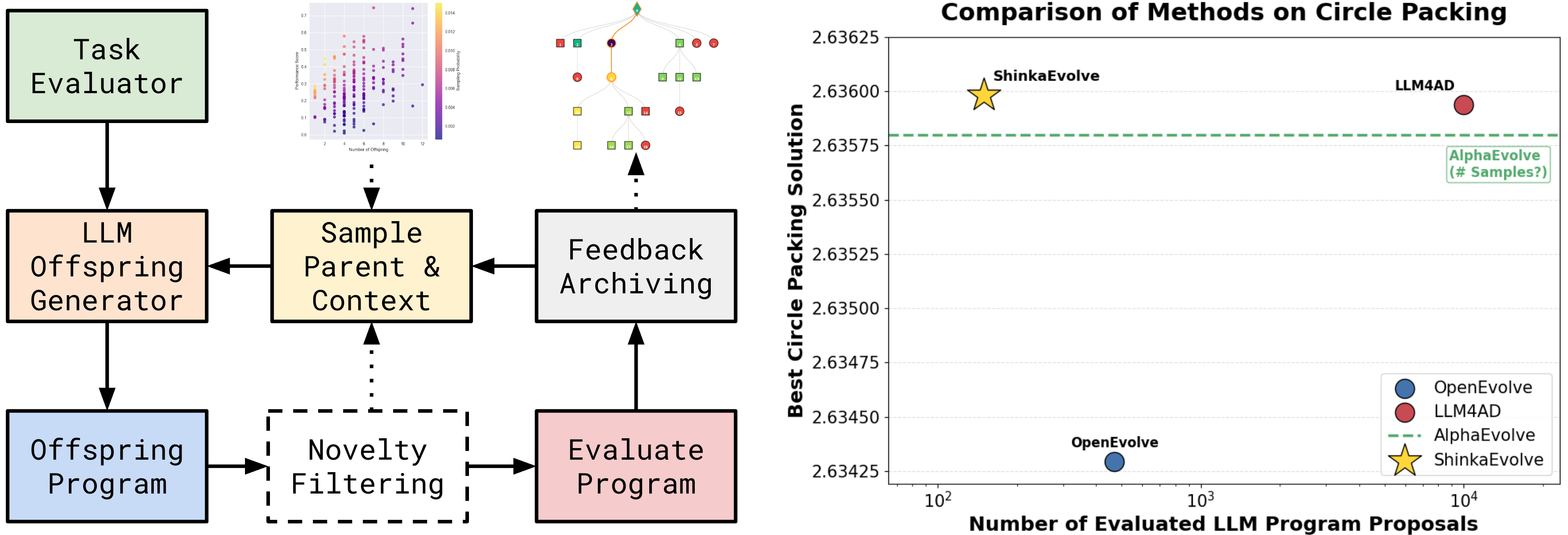
- OpenEvolve: An open-source implementation of AlphaEvolve
- LLM4AD: A Platform for Algorithm Design with Large Language Model
If you use ShinkaEvolve in your research, please cite it as follows:
@article{lange2025shinka,
title={ShinkaEvolve: Towards Open-Ended And Sample-Efficient Program Evolution},
author={Lange, Robert Tjarko and Imajuku, Yuki and Cetin, Edoardo},
journal={arXiv preprint arXiv:2509.19349},
year={2025}
}