This project demonstrates a distributed, dataspace-enabled architecture for optimizing thermoforming machine parameters (temperature, pressure, cycle time) using machine learning. It involves three key participants: a machine manufacturer, a plastic packaging producer (machine operator), and an ML service provider. Operators share labeled data—including material properties and machine settings—via secure dataspace connectors. The ML service provider processes this data and trains regression models using PyTorch, managing the model lifecycle with MLflow. These models are then deployed by the machine manufacturer as a value-added service. The architecture leverages the FastIoT microservice framework and NATS messaging for scalable, containerized communication. This setup enables secure data sharing, specialization across roles, and efficient, continuous model retraining and deployment in real industrial environments.
This Demonstration is part of the research project KIOptipack funded by the German Federal Ministry of Education and Research (BMBF). The demonstrator showcases how to realise a minimalistic version the proposed architecture in the project. Please note that in this implementation, dataspaces are not fully implemented. In Particular only the data-plane is implemented, contract management is not implemented. We aim to realise a full implementation of the architecture towards the end of the project (End of 2025). For futer developments of the Dataspace connector please check out the Eclipse Dataspace project.
This demonstrator focues on showcasis how model lifecycle management can be realised using the FastIOT framework, which is used in the project to connect machines as microservices. This Repository is supplementary material for the technical communication "Machine Learning Lifecycle Management Using Dataspaces for Optimized Machine Parameterization in Recycled Plastic Packaging". Below you can find a figure of the architecture of the demonstrator.

Please have a look at the publication for more details on the architecture and the implementation. This Demonstrator was originally showcased at the Open Hub Days 2024 in Dresden, Germany. Together with a first version of the Dataspace Connector incoperated into the FastIoT System, which is not yet publicly available.
The dataset contains labeled datapoints related to material validation processes for thermoforming equipment. Each datapoint reflects a specific use case or validation scenario, including information on the material used, equipment configuration, validation method, and outcome.
Thermoforming machine manufacturers typically offer a predefined material portfolio aligned with their equipment specifications. Converters can select suitable materials based on the intended application. To ensure contractual performance targets are met, manufacturers validate the machine's efficiency using standard materials. Using alternative materials is generally at the converter's own risk. However, some manufacturers support formal validation of unapproved materials—either through practical testing on identical or comparable machines or via structured methods such as Design of Experiments (DOE). These validation processes are typically completed within one day based on prior experience.
Each datapoint captures the relevant parameters and results from these validation efforts.
{
"ListeKomponenten": ["K000055", "K000057"], // List of materials (id or material name)
"Massenanteile": [0.5, 0.5], // mass ratios of the materials (unit: g/g)
"Flächenanteilmodifiziert": 0, // modified surface (unit: %)
"Geometrie": "Quader", // geometry (unit: list of types)
"Kopfraumatmosphäre": None, // headspace atmosphere (unit: Pa)
"Masse": None, // mass (unit: g)
"Verpackungstyp": "Folie", // packaging type
"CAD": None, // link to CAD file
"RauheitRa": 0.08666666666666667, // roughness Ra (unit: µm)
"RauheitRz": 0.924, // roughness Rz (unit: µm)
"Trübung": 216.1, // haze (unit: HLog)
"Glanz": 36.7, // gloss (unit: GE)
"Dicke": 738.6666666666666, // thickness (unit: µm)
"Emodul": 807.9225728004443, // elastic modulus (unit: MPa)
"MaximaleZugspannung": 33.22942107172407, // maximum tensile stress (unit: MPa)
"MaximaleLängenänderung": 14.57795412214027, // maximum elongation (unit: %)
"Ausformung": 1, // forming process rating (unit: class (1 to 6))
"Kaltverfo": 1, // cold forming rating (unit: class (1 to 3))
"Temp": 300, // [LABEL] temperature (unit: °C)
"Zeit": 12, // [LABEL] time (unit: s)
"Druck": 4.33 // [LABEL] pressure (unit: bar)
}Temperature ("Temp"), time ("Zeit"), and pressure ("Druck") are the target variables for the machine learning model.
Running the demonstrator is a bit complicated, due to its distributed nature and the use of different technologies. Please make sure to have the following software installed on your machine:
- Docker (for example Docker Desktop)
- MongoDB (for example MongoDB Community Edition)
- Python 3.9 or higher (for example Anaconda)
For Troubleshooting, you can check out this setup video of a similar technology stack.
The demonstrator uses MongoDB as a database to store the data. FastIoT's MongoDB connector is required to connect the MongoDB database using a username and password. It is not possible to connect to the database without a username and password (even though when you can access it without password protection in the MongoDB shell or MongoDB Explorer). To set up the MongoDB database, please follow these steps:
- make sure MongoDB is running on your machine. You can check this by running the following command in the terminal:
sudo systemctl status mongodIf MongoDB is not running, you can start it by running the following command
sudo systemctl start mongod- Create username and password in the mongo shell:
use admin db.createUser({ user: "fiot", pwd: "fiotdev123", roles: [ { role: "root", db: "admin" } ] })This username and password is used this repository to connect to the MongoDB database. If you want to use a different username and password, you need to change the corresponding Microservice.
First, clone the repository to your local machine. You can do this by running the following command in your terminal:
git clone https://github.com/Alexander-Nasuta/openhub-demo.gitMost Developers use a virtual environment to manage the dependencies of their projects.
I personally use conda for this purpose.
When using conda, you can create a new environment with the name 'openhub-demo' following command:
conda create -n openhub-demo python=3.11Feel free to use any other name for the environment or a more recent version of python. Activate the environment with the following command:
conda activate openhub-demoReplace openhub-demo with the name of your environment, if you used a different name.
You can also use venv or virtualenv to create a virtual environment. In that case please refer to the respective documentation.
Next, you need to install the dependencies for each Dataspace Participant (FastIOT Project).
pip install -r ./anlagenbetreiber/requirements.txtpip install -r ./dienstleister/requirements.txtpip install -r ./hersteller/requirements.txtNext create the FastIoT configuration for each Dataspace Participant (FastIOT Project).
cd ./anlagenbetreiberfiot create configcd ../dienstleisterfiot create configcd ../herstellerfiot create configThe simplest way to start the Nats Broker is to use FastIoTs integration_test deployment.
cd ./anlagenbetreiberfiot start integration_testThe MLflow server is used to manage the machine learning lifecycle, including experimentation, reproducibility, and deployment. To start the MLflow server, run the following command in your terminal:
mlflow server --host 127.0.0.1 --port 8080The Microservices can be started by running the run.py script in each directory.
So for example for starting the MongoDB Database Service machinen_parametrierung_service.py run the script ./anlagenbetreiber/src/anlagenbetreiber_services/machinen_parametrierung/run.py
The Services depend on each other, so to avoid warning and error messages, please run the services in the following order:
- (make sure the Nats Broker, MongoDB, Docker, MLflow are running)
- MongoDB Service (
mongo_databasein./anlagenbetreiber/src/anlagenbetreiber_services) - Dataspace Connector Service (Machine Operator) (
edc_anlagenbetreiberin./anlagenbetreiber/src/edc_anlagenbetreiber) - Data Processing Service (
data_processingin./dienstleister/src/dienstleister_services) - Dataspace Connector Service (ML Service Provider) (
edc_dienstleisterin./anlagenbetreiber/src/anlagenbetreiber_services) - ML Model Training Service (
ml_trainingin./dienstleister/src/dienstleister_services) - ML Serving Service (
ml_servingin./hersteller/src/hersteller_services) - Dataspace Connector Service (Machine Manufacturer) (
edc_herstellerin./hersteller/src/hersteller_services) - Prediction Consuming Service (
machinen_parametrierungin./anlagenbetreiber/src/anlagenbetreiber_services)
Here are some Screenshots and Videos of the running System
In MongoExplorer you can see the data that is stored in the MongoDB database.

Over time you should see a bunch of runs in MLflow in the Experiments tab.

The detailed view of a run looks like this:


The trained models will appear in the Models tab.

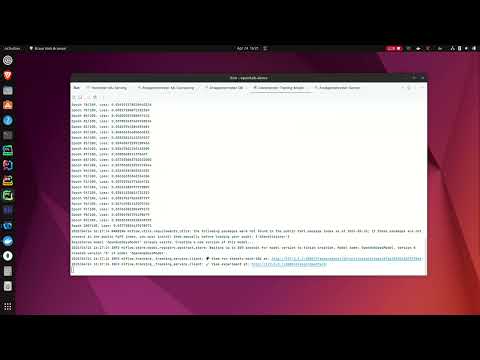
Below you can find the console logs of the Model Hosting Service with two example predictions.

In this Video you can see some console logs of the running system.
Video on Youtube:
Video on Github: Watch Video: Screencast.webm
This section contains a summary of the background and related work in the field of machine learning lifecycle management and its application in the context of recycled plastic processing that did not fit into the paper due its page limit. We added it here for interested readers.
Recent research has explored the use of machine learning techniques to predict and optimize process parameters.
Pelzer et al. have shown that Invertible Neural Networks (INNs) are promising for generating process parameters to achieve desired part properties with high accuracy.
Pazhamannil et al. and Manoharan et al. successfully employed Artificial Neural Networks (ANNs) to predict tensile strength based on various process parameters, demonstrating good agreement with experimental results.
Seifert et al. (2025) developed an analytical model to predict the shear viscosity of polypropylene compounds, a key parameter for ensuring efficient processing and consistent product quality.
In a related study, Seifert et al. (2024) proposed an analytical model for predicting the tensile modulus of polypropylene compounds with various fillers and additives. Their work also compared the model’s performance against an artificial neural network, highlighting the strengths and limitations of both approaches.
Other methodologies for optimizing plastic extrusion processes include artificial neural networks, fuzzy logic, genetic algorithms, and response surface methodology (Raju et al.).
Overall, it can be stated that the integration of machine learning techniques and analytical models has greatly enhanced the prediction and optimization of process parameters in polymer processing.
Thopalle et al. presents a unified ML approach for artifact management in Jenkins CI/CD pipelines, addressing multiple functions such as retention prediction and compression optimization with a single model.
Schlegel and Sattler provide an overview of systems and platforms that support the management of ML artifacts, including datasets, models, and configurations. They establish assessment criteria and apply them to over 60 systems. Additionally, Schlegel and Sattler define a typical machine learning lifecycle with four stages: the Requirements, Data-oriented, Model-oriented, and Operations-oriented stages.
The Requirements Stage focuses on defining the functional and technical prerequisites of the ML model, determining the model types and data sources best suited for the given problem. The Data-oriented Stage encompasses data collection, cleaning, labeling, and feature engineering to ensure the availability of high-quality datasets for training. The Model-oriented Stage includes model selection, training, evaluation, and optimization to develop a robust ML model. Finally, the Operations Stage involves model deployment, continuous monitoring, and integration with production systems, ensuring optimal performance and reliability.

Besides the lifecycle model by Schlegel and Sattler, alternative process models for ML lifecycle management exist.
Wirth and Hipp introduced CRISP-DM (Cross Industry Standard Process for Data Mining), a widely used framework that provides a structured approach to data mining and machine learning projects.
Another notable extension is Huber et al.'s DMME (Data Mining Methodology for Engineering Applications), which builds upon CRISP-DM by integrating engineering-specific considerations for a more holistic approach to ML lifecycle management.
Overall, it can be stated that numerous concrete implementations exist for achieving lifecycle management. Effectively realizing an ML lifecycle system corresponds to integrating elements of the process model, such as the lifecycle stages introduced by Schlegel and Sattler, into a cohesive software architecture.
- Abdullah et al.
- Abdullah, Jamaluddin, Shanb, LWAI, and Ismail, H (2016). “Optimization of injection moulding process parameters for recycled High Density Polyethylene (rHDPE) using the Taguchi method.” Int. J. Mech. Prod. Eng, 4, 76–81.
- Fei et al.
- Fei, NC, Kamaruddin, S, Siddiquee, AN, and Khan, ZA (2011). “Experimental investigation on the recycled HDPE and optimization of injection moulding process parameters via Taguchi method.” Int J Mech Mater Eng, 6(1), 81–91.
- Panneerselvam and Turan
- Panneerselvam, Vivekanandan, and Turan, Faiz Mohd (2020). “Multi response optimisation of injection moulding process parameter using Taguchi and desirability function.” Intelligent Manufacturing and Mechatronics: Proceedings of the 2nd Symposium on Intelligent Manufacturing and Mechatronics--SympoSIMM 2019, 8 July 2019, Melaka, Malaysia, 252–264.
- Raju et al.
- Raju, Geo, Sharma, Mohan Lal, and Meena, Makkan Lal (2014). “Recent methods for optimization of plastic extrusion process: a literature review.” Int. J. Adv. Mech. Eng, 4(6), 583–588.
- Hauff et al.
- Hauff, Marco, Comet, Lina Molinas, Moosmann, Paul, Lange, Christoph, Chrysakis, Ioannis, and Theissen-Lipp, Johannes (2024). “FAIRness in Dataspaces: The Role of Semantics for Data Management.” The Second International Workshop on Semantics in Dataspaces, co-located with the Extended Semantic Web Conference.
- Lu et al.
- Lu, Junyu, Yang, Laurence T, Guo, Bing, Li, Qiang, Su, Hong, Li, Gongliang, and Tang, Jun (2021). “A sustainable solution for IoT semantic interoperability: Dataspaces model via distributed approaches.” IEEE Internet of Things Journal, 9(10), 7228–7242.
- Theissen-Lipp et al.
- Theissen-Lipp, Johannes, Decker, Stefan, and Curry, Edward (2023). “The First International Workshop on Semantics in Dataspaces.” Companion Proceedings of the ACM Web Conference 2023, 1439–1439.
- Atzori et al.
- Atzori, Maurizio, Ciaramella, Angelo, Diamantini, Claudia, Martino, BD, Distefano, Salvatore, Facchinetti, Tullio, Montecchiani, Fabrizio, Nocera, Antonino, Ruffo, Giancarlo, Trasarti, Roberto, et al. (2024). “Dataspaces: Concepts, Architectures and Initiatives.” CEUR WORKSHOP PROCEEDINGS, 3606.
- Hai et al.
- Hai, Rihan, Geisler, Sandra, and Quix, Christoph (2016). “Constance: An intelligent data lake system.” Proceedings of the 2016 international conference on management of data, 2097–2100.
- Sukhobokov et al.
- Sukhobokov, Artem A, Gapanyuk, Yury E, Zenger, Anna S, and Tsvetkova, Alyona K (2022). “The concept of an intelligent data lake management system: Machine consciousness and a universal data model.” Procedia Computer Science, 213, 407–414.
- Serban et al.
- Serban, Floarea, Vanschoren, Joaquin, Kietz, Jörg-Uwe, and Bernstein, Abraham (2013). “A survey of intelligent assistants for data analysis.” ACM Computing Surveys (CSUR), 45(3), 1–35.
- Walker and Alrehamy
- Walker, Coral, and Alrehamy, Hassan (2015). “Personal data lake with data gravity pull.” 2015 IEEE Fifth International Conference on Big Data and Cloud Computing, 160–167.
- Schlegel and Sattler
- Schlegel, Marius, and Sattler, Kai-Uwe (2023). “Management of machine learning lifecycle artifacts: A survey.” ACM SIGMOD Record, 51(4), 18–35.
- Thopalle
- Thopalle, Praveen Kumar (2022). “A Unified Machine Learning Approach for Efficient Artifact Management in Jenkins CI/CD Pipelines.” Journal of Artificial Intelligence & Cloud Computing.
- Pelzer et al.
- Pelzer, Lukas, Posada-Moreno, Andrés Felipe, Müller, Kai, Greb, Christoph, and Hopmann, Christian (2023). “Process Parameter Prediction for Fused Deposition Modeling Using Invertible Neural Networks.” Polymers, 15(8), 1884.
- Pazhamannil et al.
- Pazhamannil, Ribin Varghese, Govindan, P, and Sooraj, P (2021). “Prediction of the tensile strength of polylactic acid fused deposition models using artificial neural network technique.” Materials Today: Proceedings, 46, 9187–9193.
- Manoharan et al.
- Manoharan, Karthic, Chockalingam, K, and Ram, S Shankar (2020). “Prediction of tensile strength in fused deposition modeling process using artificial neural network technique.” AIP Conference Proceedings, 2311(1).
- Roach et al.
- Roach, Devin J, Rohskopf, Andrew, Leguizamon, Samuel, Appelhans, Leah, and Cook, Adam W (2023). “Invertible neural networks for real-time control of extrusion additive manufacturing.” Additive Manufacturing, 74, 103742.
- Seifert et al. (2025)
- Seifert, Lukas, Leuchtenberger-Engel, Lisa, and Hopmann, Christian (2025). “Development of an Analytical Model for Predicting the Shear Viscosity of Polypropylene Compounds.” Polymers, 17(2), 126.
- Seifert et al. (2024)
- Seifert, Lukas, Leuchtenberger-Engel, Lisa, and Hopmann, Christian (2024). “Development of an Analytical Model for Predicting the Tensile Modulus of Complex Polypropylene Compounds.” Polymers, 16(23), 3403.
- Klaeger and Merker
- Klaeger, Tilman, and Merker, Konstantin (2022). “FastIoT--A framework and holistic approach for rapid development of IIoT systems.” arXiv preprint arXiv:2201.13243.
- European Commission
- European Commission (2018). “A European Strategy for Plastics in a Circular Economy.” COM(2018) 28 final. Accessed: 2025-02-20.
- Andrady and Neal
- Andrady, Anthony L, and Neal, Mike A (2009). “Applications and societal benefits of plastics.” Philosophical Transactions of the Royal Society B: Biological Sciences, 364(1526), 1977–1984.
- Raj and Matche
- Raj, Baldev, and Matche, R.S. (2011). “Safety and regulatory aspects of plastics as food packaging materials.” Multifunctional and Nanoreinforced Polymers for Food Packaging, 669–691.
- Velásquez et al.
- Velásquez, Eliezer, Guerrero Correa, Matías, Garrido, Luan, Guarda, Abel, Galotto, María José, and López de Dicastillo, Carol (2021). “Food Packaging Plastics: Identification and Recycling.” Recent Developments in Plastic Recycling, 311–343.
- Geueke et al.
- Geueke, Birgit, Groh, Ksenia, and Muncke, Jane (2018). “Food packaging in the circular economy: Overview of chemical safety aspects for commonly used materials.” Journal of Cleaner Production, 193, 491–505.
- Ballestar de las Heras et al.
- Ballestar de las Heras, Ricardo, Colom, Xavier, and Cañavate, Javier (2024). “Comparative Analysis of the Effects of Incorporating Post-Industrial Recycled LLDPE and Post-Consumer PE in Films: Macrostructural and Microstructural Perspectives in the Packaging Industry.” Polymers, 16(7), 916.
- Hinczica et al.
- Hinczica, Jessica, Messiha, Mario, Koch, Thomas, Frank, Andreas, and Pinter, Gerald (2022). “Influence of Recyclates on Mechanical Properties and Lifetime Performance of Polypropylene Materials.” Procedia Structural Integrity, 42, 139–146.
- Strangl et al.
- Strangl, Miriam, Ortner, Eva, Fell, Tanja, Ginzinger, Tanja, and Buettner, Andrea (2020). “Odor characterization along the recycling process of post-consumer plastic film fractions.” Journal of Cleaner Production, 260, 121104.
- PlasticsEurope
- PlasticsEurope (2020). “Plastics—The Facts 2020.” Accessed: 2024-11-01.
- Welten et al.
- Welten, Sascha, Mou, Yongli, Neumann, Laurenz, Jaberansary, Mehrshad, Ucer, Yeliz Yediel, Kirsten, Toralf, Decker, Stefan, and Beyan, Oya (2022). “A privacy-preserving distributed analytics platform for health care data.” Methods of information in medicine, 61(S 01), e1–e11.
- Huber et al.
- Huber, Steffen, Wiemer, Hajo, Schneider, Dorothea, and Ihlenfeldt, Steffen (2019). “DMME: Data mining methodology for engineering applications--a holistic extension to the CRISP-DM model.” Procedia Cirp, 79, 403–408.
- Wirth and Hipp
- Wirth, Rüdiger, and Hipp, Jochen (2000). “CRISP-DM: Towards a standard process model for data mining.” Proceedings of the 4th international conference on the practical applications of knowledge discovery and data mining, 1, 29–39.
This project uses sphinx for generating the documentation.
It also uses a lot of sphinx extensions to make the documentation more readable and interactive.
For example the extension myst-parser is used to enable markdown support in the documentation (instead of the usual .rst-files).
It also uses the sphinx-autobuild extension to automatically rebuild the documentation when changes are made.
By running the following command, the documentation will be automatically built and served, when changes are made (make sure to run this command in the root directory of the project):
sphinx-autobuild ./docs/source/ ./docs/build/html/This project features most of the extensions featured in this Tutorial: Document Your Scientific Project With Markdown, Sphinx, and Read the Docs | PyData Global 2021.
In the future, we plan to implement the following features. This will result in a new Repository. This Repo will be archived.
- Add contract negotiation: replace the current Dataspace Connector Service with a Released Version of the Eclipse Dataspace Connector
- Sequential Release of Labelled Data: currently the hole dataset is added to the database at once. In the future, we plan to release the data in a sequential manner. That way one can observe how the trained models get better over time.
If you have any questions or feedback, feel free to contact me via email or open an issue on repository.
This project and the corresponding technical communication was made possible through the contributions of the following individuals:
- Alexander Nasuta, M.Sc. – Conceptualization, Software, Writing
- Sylwia Olbrych, M.Sc. – Conceptualization, Writing
- Prof. Christoph Quix – Conceptualization, Writing
- Dipl.-Ing. Tim Kaluza – Conceptualization
- Dipl.-Ing. Florian Schaller – Data Curation
- Sabrina Steinert, M.Sc. – Conceptualization
- Hans Aoyang Zhou, M.Sc. – Writing (Review)
- Dr. Anas Abdelrazaq – Writing (Review)
- Prof. Robert H. Schmitt – Supervision, Funding Acquisition
Distributed under the MIT License. See LICENSE.txt for more information.